regain
regain is a search engine similar to web search engines like Google, with the difference that you don't search the web, but your own files and documents. Using regain you can search through large portions of data (several gigabytes!) in split seconds!
This is possible by using a search index. regain crawles through your files or webpages, extracts all text and puts it in a smart search index. All this happens in the background. So if you want to search something you get the results immediately.
There are two versions of regain: The desktop search and the server search. The desktop search is to be used on a normal desktop computer and it offers you a fast search for documents or intranet webpages. The server search you can install on web servers. It provides searching functionality for a website or for intranet fileservers.
regain is written in Java and thus applicable on all Java compatible platforms (amongst others Windows, Linux, Mac OS, Solaris). The server search works with Java Server Pages (JSPs) and a tag library, the desktop search comes with its own small webserver.
regain is released under the open source license LGPL (Lesser General Public License). I.e. regain may be used for free without any temporal limit.
You can find more information about the details of regain here.
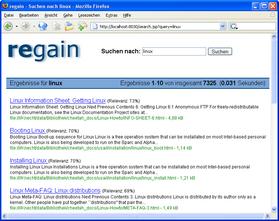
Another viable option in place of Google Desktop Search, though not as many docked windows and indexing limits as the latter.
This is possible by using a search index. regain crawles through your files or webpages, extracts all text and puts it in a smart search index. All this happens in the background. So if you want to search something you get the results immediately.
There are two versions of regain: The desktop search and the server search. The desktop search is to be used on a normal desktop computer and it offers you a fast search for documents or intranet webpages. The server search you can install on web servers. It provides searching functionality for a website or for intranet fileservers.
regain is written in Java and thus applicable on all Java compatible platforms (amongst others Windows, Linux, Mac OS, Solaris). The server search works with Java Server Pages (JSPs) and a tag library, the desktop search comes with its own small webserver.
regain is released under the open source license LGPL (Lesser General Public License). I.e. regain may be used for free without any temporal limit.
You can find more information about the details of regain here.

Another viable option in place of Google Desktop Search, though not as many docked windows and indexing limits as the latter.


Comments